 この記事にはプロモーションが含まれていることがあります
この記事にはプロモーションが含まれていることがあります
あなたのウェブサイトやブログの内容をAIに学習させないようにして、自分のコンテンツを守る方法について紹介します。自分の身は自分で守りましょう!
AIはどうやって学習しているか
生成AIは、インターネット上でアクセスできる様々なテキストデータを収集して、巨大なデータベースに集積しています。その一連のプロセスを学習と呼んでいます。
そして、その学習した情報をもとに質問に対する回答を生成しています。
もちろん、その学習対象には、あなたのブログも含まれています。つまりあなたが精魂込めて書いた記事をAIは学習して質問者からの回答に答えてしまうため、あなたのブログにアクセスしなくてもよくなってしまうわけです。
AIで生成した内容を丸写ししているようなブログはどうでもよいかも知れませんが、あなたの経験や考えなどオリジナリティのあるコンテンツを掠め取られてしまうのはあまり気持ちの良いものではありませんね。
そんな時は、AIのデータ収集をブロックすることでAIの学習の対象から外してしまいましょう。
AIのクローラーアクセスをブロックする方法
現状、次の2つのAIが有名です。
- OpenAI社のChatGPT
- Google社のGemini(旧:Bard)
どちらのAIも開発元から公式で学習対象外にする方法が公開されています。やり方は、robots.txtのUser-AgentヘッダにAI学習用クローラーを指定します。
Webサイトやブログを運営している人ならお馴染みのrobots.txt。検索エンジンのクローラーやロボットに対して、特定のウェブページやディレクトリへのアクセスの許可や禁止を指定するために使うファイルです。
ファイル名から分かる通り、ただのテキストファイルです。メモ帳で書いてWebサーバーのコンテンツルートフォルダに格納することで効果を発揮します。
OpenAI – ChatGPT
OpenAIの生成AI、ChatGPTの学習対象から外すコード:User-agent: GPTBot
User-agent: GPTBot
Disallow: /
User-agent: ChatGPT-User
Disallow: /(引用)OpenAI Documentation – GPTbot
Google – Gemini(旧:Bard)
Googleの生成AI、Geminiの学習対象から外すコード:User-agent: Google-Extended
User-agent: Google-Extended
Disallow: /(引用)Google検索セントラル – Googleクローラー
設定方法
次にこのコードをどこに設定していくのか解説します。
Webサーバ、またはブログのドキュメントルートにrobots.txtというファイルを作成するだけです。
エックスサーバーの場合
レンタルサーバーではサーバー上のファイルを操作できるファイル管理ツールが提供されていることが多いです。
ここからはエックスサーバーの例で説明します。他のレンタルサーバーは使ったことないのですが、この辺りの操作はどこも似たような感じだと思います。
まずログインしてファイル管理ツールを起動します。エックスサーバーの場合はファイル管理です。
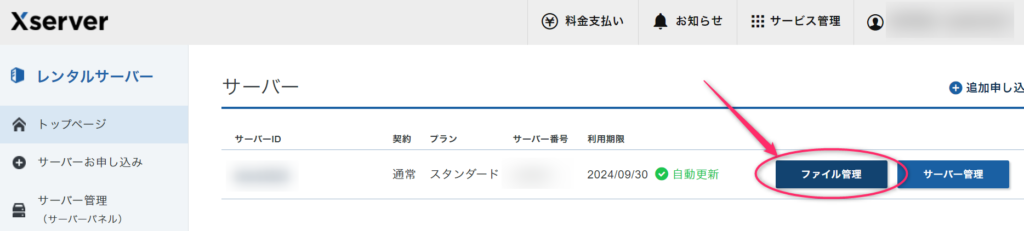
ドメイン名またはレンタルサーバのIDのフォルダを探します。
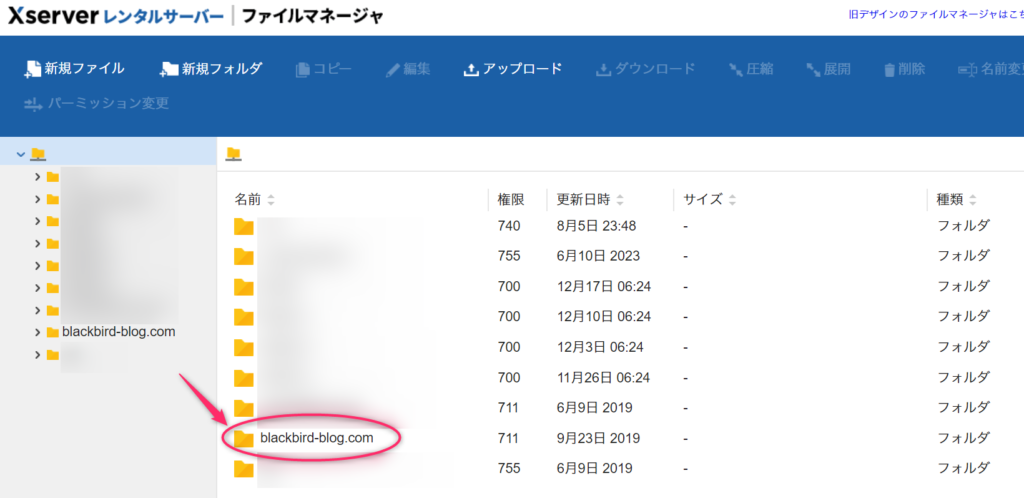
ドキュメントルートフォルダの中を表示します。私の環境ではpublic_htmlでした。
WordPressの場合、wp-adminやwp-contentフォルダがある場所がドキュメントルートとなる場合が多いです。
ドキュメントルートはみつかりましたか?
見つかったら、直下にrobots.txtファイルがあるかないか確認します。
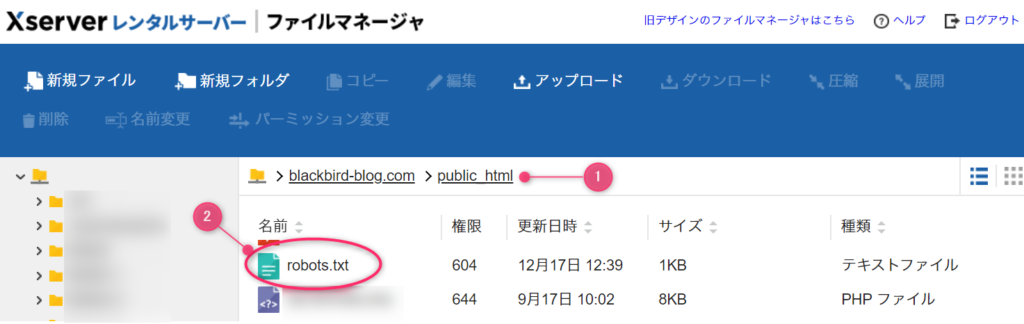
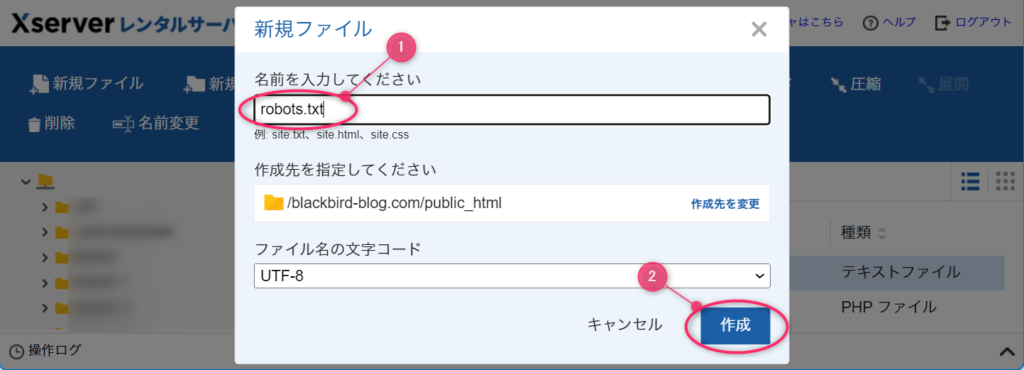
robots.txtが見つからない場合
新規作成でファイルを新しく作ります。
robots.txtがみつかった場合
そのファイルを編集します。
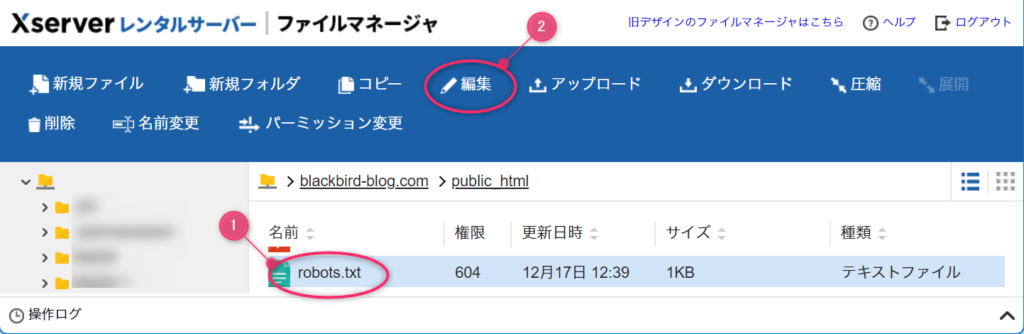
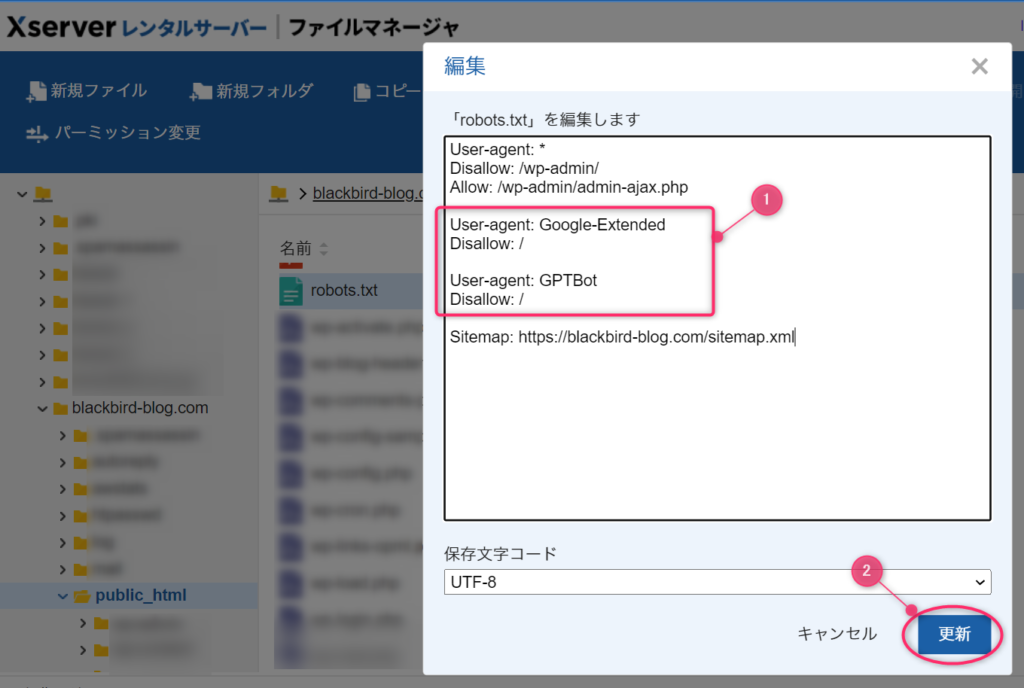
robots.txtファイルはただのテキストファイルなので、編集で開いてAIクローラーからのアクセスを拒否する設定を追記します(①)。
追記したら更新(②)ボタンを押して完了です。
ブラウザ上で直接編集できない場合(FTPを使う)
レンタルサーバーによってはファイル管理ツールがないものもあり、その場合は直接サーバ上のファイルを編集できないため、代わりにFTPツールを使います。
FTPツールでドキュメントルートを確認し、robots.txtが既にある場合は一度パソコンにダウンロードして編集して、アップロードしてサーバー上のrobots.txtを上書きします。
もし、robots.txtがみつからない場合は、パソコン側のメモ帳やエディタなどでrobots.txtファイルを作成してアップロードします。
設定を確認する方法
robots.txtがブラウザ上で参照できるか確認
きちんと設定できたか確認する方法は簡単です。
あなたのブログのトップページのURLの後ろに /robots.txt を付けてアクセスして設定した内容が表示されればOKです。
これはうちのブログの場合です。
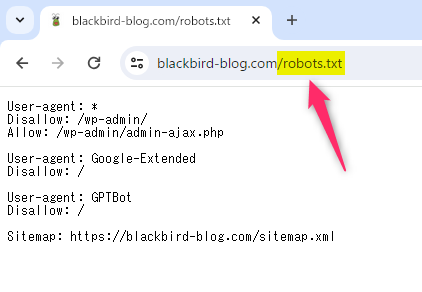
うまく設定できた方はこれでブロック完了です。おつかれさまでした!
エラーケース1:403エラー
403エラーになってしまう場合は、robots.txtファイルの設置はできましたが、ファイルのアクセス権限の設定にミスしている可能性があります。
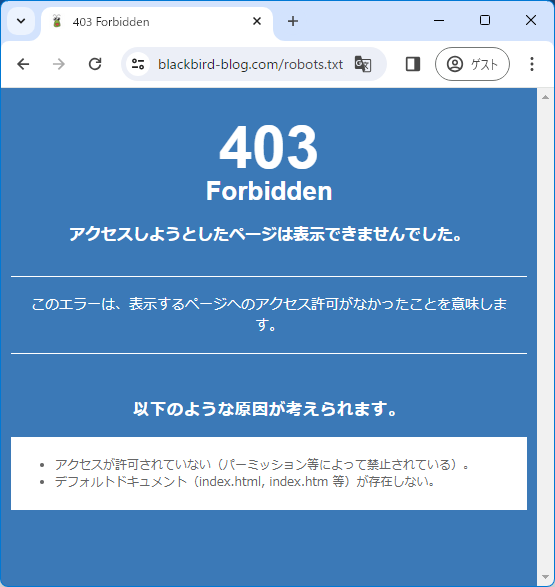
この場合は、robots.txtのパーミッションを変更します。600だとrobots.txtを作成したあなたしかアクセスできません。
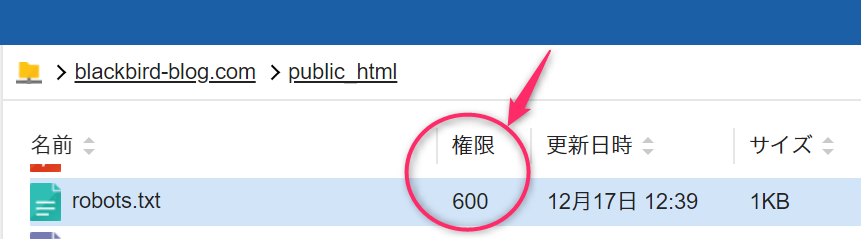
ブラウザから不特定多数の訪問者やクローラーから見れるようにするには、①robots.txtファイルの②パーミッションの変更で、③その他の読み取りを許可して④更新します。
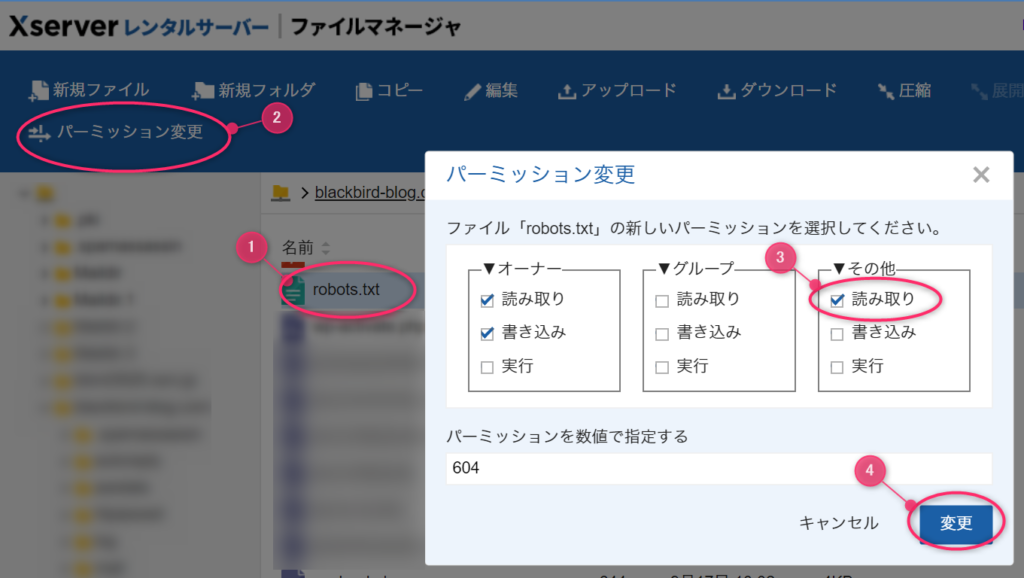
これで再度ブラウザからアクセスしてみてください。設定内容が表示されると思います。
エラーケース2:404エラー
404エラーになってしまう場合は、ドキュメントルート直下にrobots.txtファイルが設置できていない可能性が高いです。ドキュメントルートの位置を再確認してください。
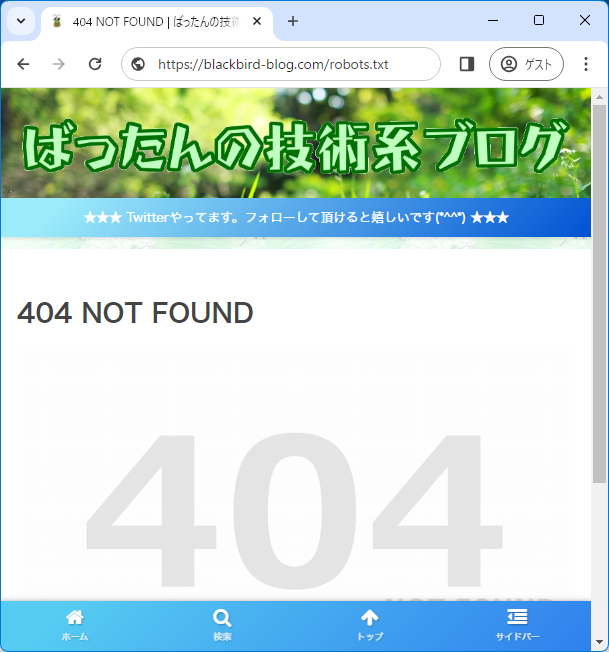
これで再度ブラウザからアクセスしてみてください。設定内容が表示されると思います。
それでは、また!


コメント