 この記事にはプロモーションが含まれていることがあります
この記事にはプロモーションが含まれていることがあります
今回やること
AWSのストレージサービス(S3)にバケットAとBを作って、バケットAにファイルをアップロードしたら、自動でそのファイルをバケットBにコピーしたり、移動させたりするプログラムを作ってみます。
このぐらいの簡単な処理ならEC2などでサーバー立ててプログラム実行環境を構築するより、今どきのサーバレスでプログラムだけ書いてささっと処理してしまった方がコストが安いですし、スマートです。
そしてAWSでサーバレス処理が実行できるサービスが「AWS Lambda」です。
Lambdaってなに?
一般的にネットサービスを構築する時にはプログラムを実行するアプリケーショサーバが必須です。そしてそのアプリケーションサーバの基礎部分に当たるのがEC2です。
EC2インスタンスを立ち上げ、LinuxなどのOSをインストール、ネットワーク設定、言語の実行環境を整えて作ったアプリケーションを乗せて初めて動くものです。
しかし、Lambdaを使えば、一番最後のアプリケーションを乗せるだけで動きます。
現実世界で例えるなら、なにかの事業活動をするのに、賃貸物件を借りて什器や電子機器を準備して事務所として整えて業務開始となるのがEC2のイメージとするならば、コワーキングスペースにドロップインしてパソコンを借りてちょいと作業するイメージです。
準備
- AWSアカウント
- 少しのAWS知識
- 少しのJavaScriptの知識
AWSのアカウントは無料でできますので、まだ作成していない方はこちらの記事でアカウントの作り方を紹介していますので、ご覧になってください。
- S3: ストレージ
- Lambda: サーバレス関数
- IAM: 権限管理
S3のバケットから別のバケットへ自動でコピー・移動
大まかな流れは、まずはファイルをアップロード先のS3バケットとファイルコピー・移動先のバケットを作ります。
次にバケットへのファイルアップロードを検知したら、別のバケットへファイルをコピーする処理をLambda関数として作成します。
移動元と移動先のバケットを作成
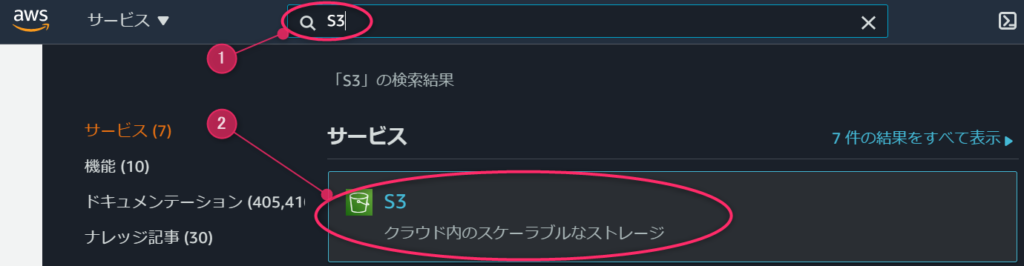
サービス検索欄に「S3」と入力し、S3が表示されたらクリックします。
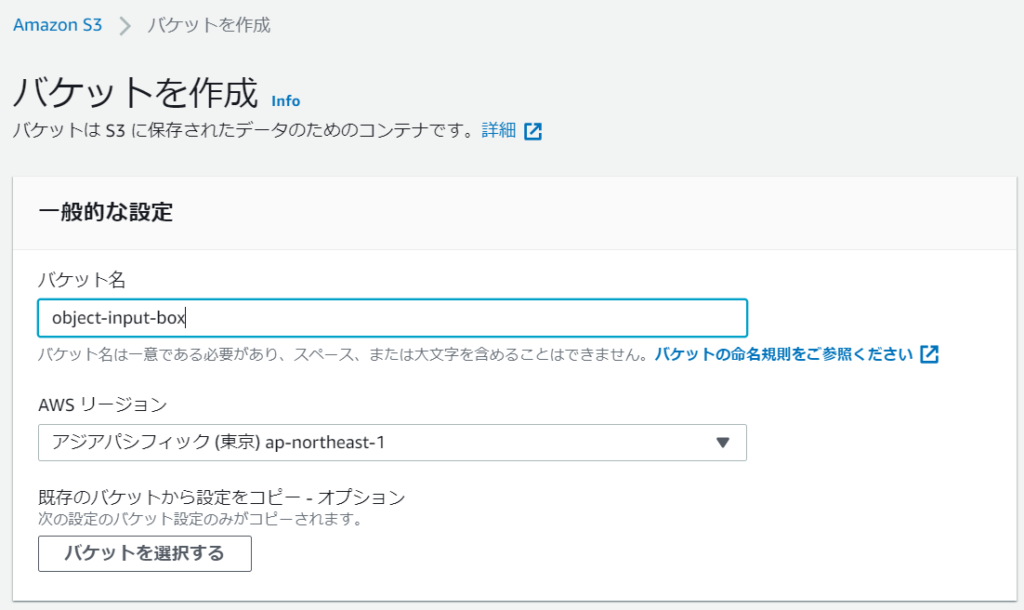
まずは、バケットを作成します。バケットとはファイルを格納するための入れ物だと思ってください。

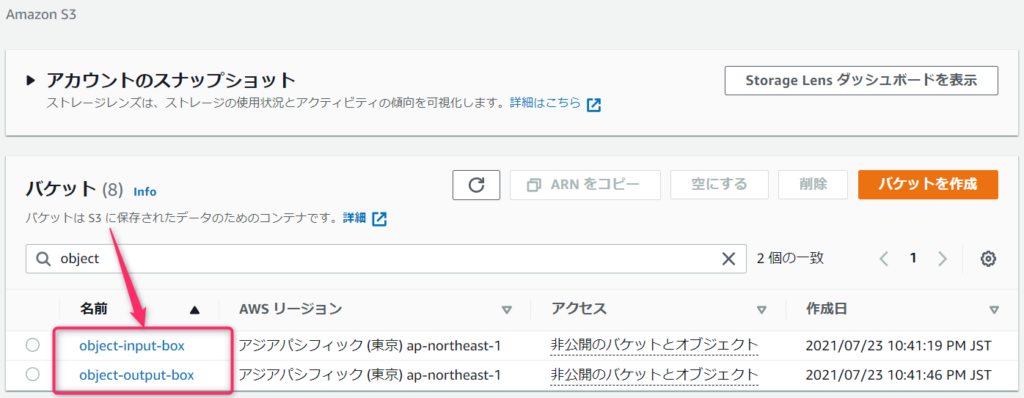
今回はバケット間でファイルをコピー・移動するので、バケットを2つ作ります。
- object-input-box
- object-output-box
今回は入力用と出力のバケットを作りました。object-inout-boxにファイルをアップロードすると、自動でobject-output-boxにコピー・移動されるようにしようと思います。
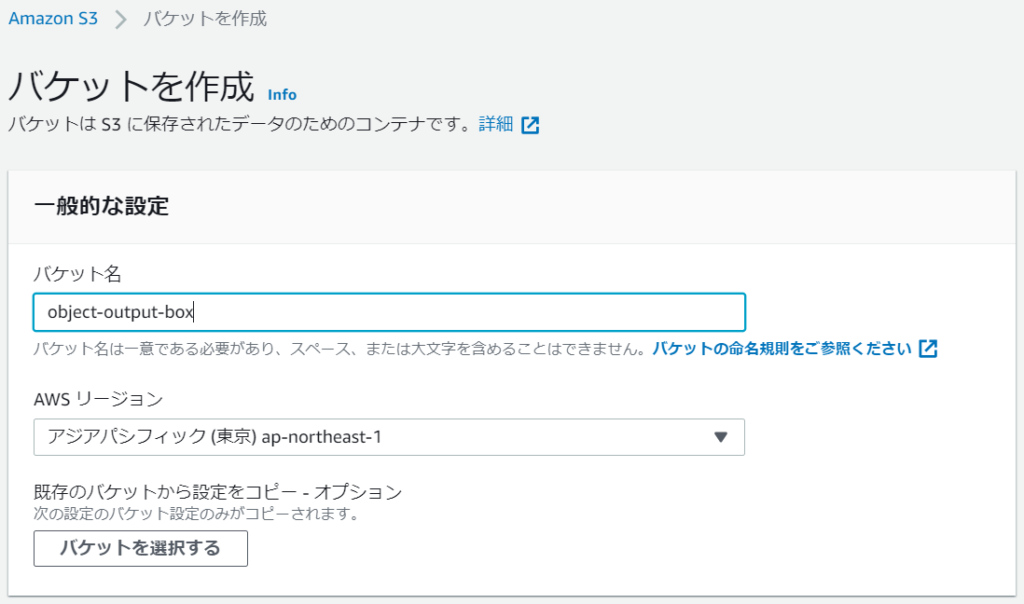
バケット名とリージョンを選択したら、バケットを作成ボタンをクリックすればバケットが作られます。
リージョンはどこでもよいです。ただこのあと作成するLambda関数を設置するリージョンと合わせる必要があります。

このように表示されてしまった場合は、バケット名を変更するか、リージョンを変更して試してください。
東京リージョンでは私がこの記事書くのに作ってしまったので作れないと思いますm(_ _)m
さて、無事に作成できたらら、バケット一覧に表示されると思います。
これでS3の設定は完了です。
Lambda関数実行用のロールを作成
次はLambda関数を実行するロールを作成します。
通常のLambda関数のロールだとCloudWatchへのログ書き込み権限ぐらいしか付与されないため、Lambda関数の処理でS3にアクセスできません。よって、S3へのアクセス権限を付ける必要があります。
いきなりLambda関数を作って、そのタイミングでロールを作ってもよいのですが、同じようなLambda関数を作る度に同じようなロールが大量生産されてしまい、後でややこしいので、先に共通で使えるロールを作ってしまいます。
サービス検索欄に「iam」と入力すると、IAMが表示されますので、これをクリックします。
画面左側のメニューから「ロール」を選択します。
ロールを作成ボタンが表示されたら、それをクリックします。
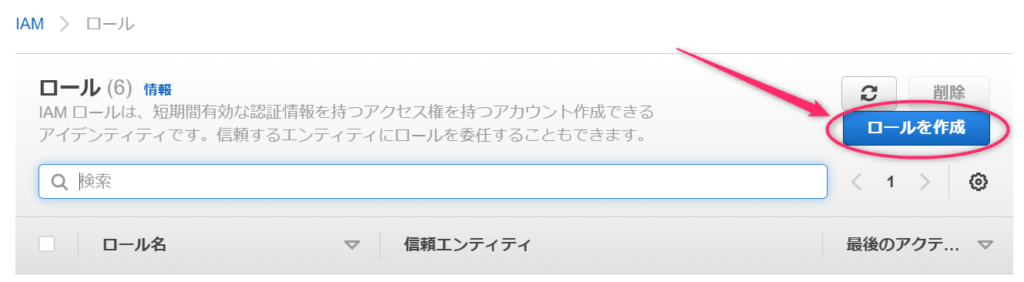
AWSサービスを選択し、ユースケースの選択で「Lambda」を選択します。私は前に一度使ったので上の方に表示されていますが、ここに表示されない場合は下の方にズラズラと並んでいる中にあると思います。
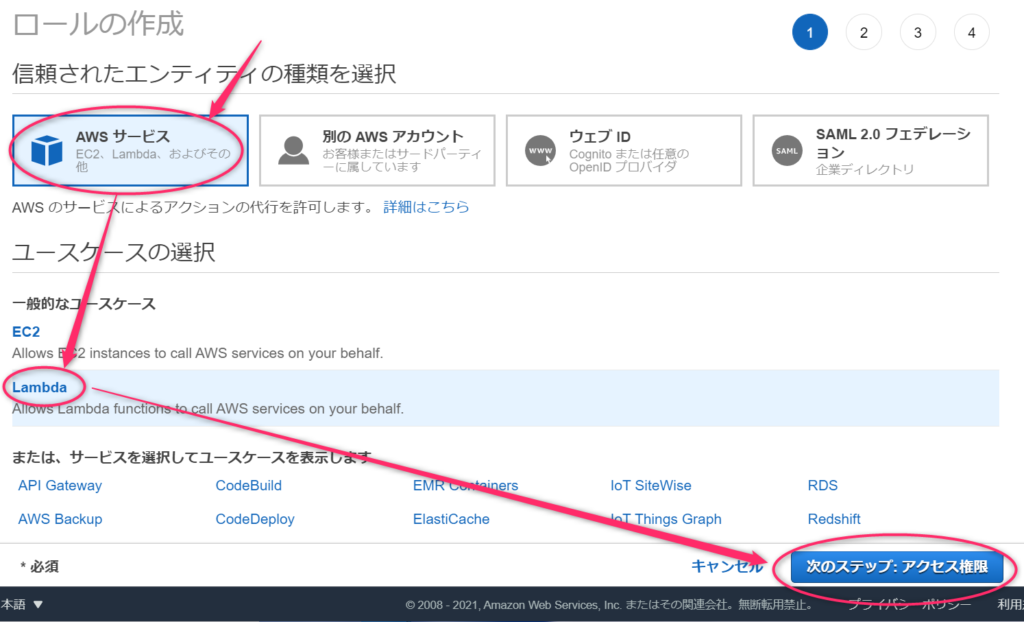
作成するロールにポリシー(権限)を付与します。
本当は必要最小限の権限に留めるのがセオリーなのですが、今回は面倒なので「AmazonS3FullAccess」を付けてS3への全操作権限を付けます。また、「AWSLambdaBaseExecutionRole」も付けて関数が動いてCloudWatchにログが残るようにします。
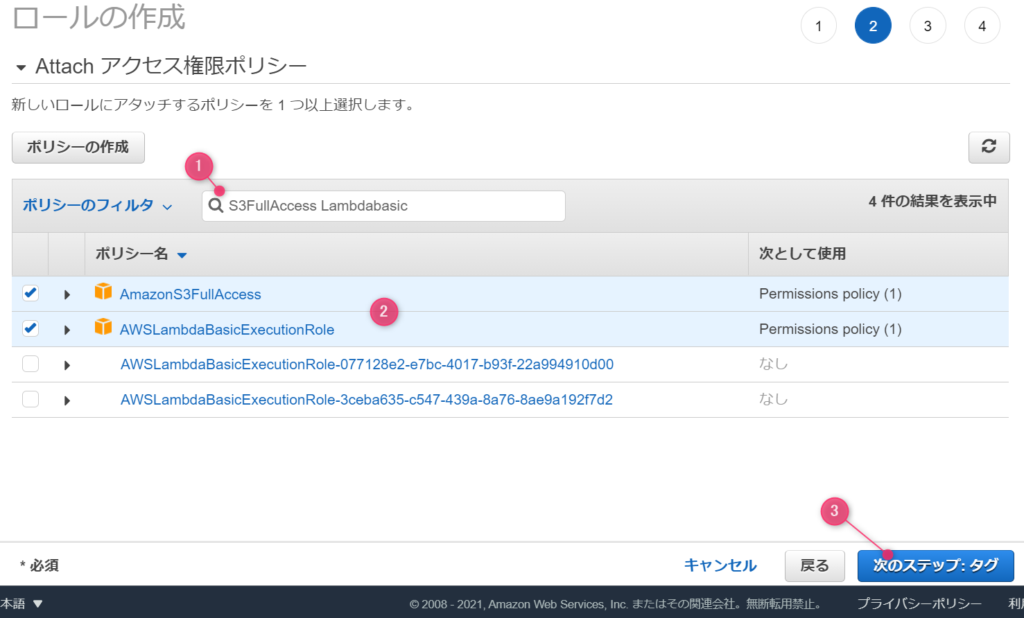
ロール名を付けます。どんな権限を持っているロールなのか分かりやすい名前がよいでしょう。適当に名前を付けるとあとで探すのが大変です。
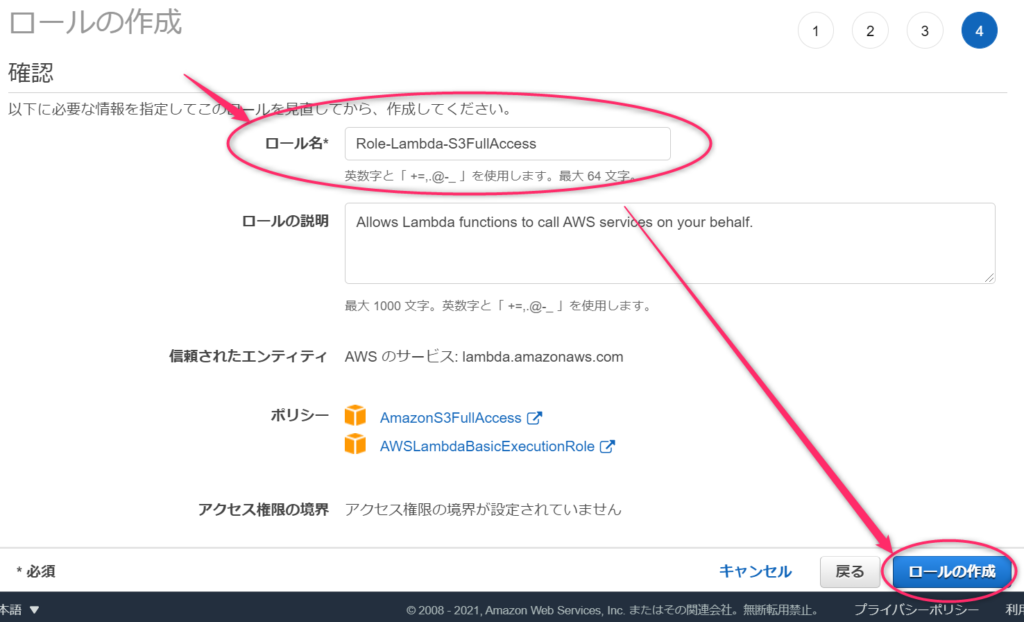
ロールのリストに作成したロールが表示されれは作成完了です。
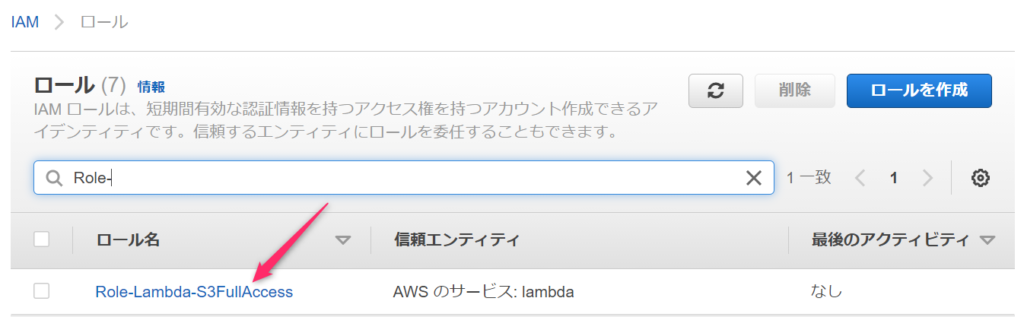
バケット間移動処理をするLambda関数を作成
ファイルの入れ物とLambda関数からS3を操作するための権限ができましたので、あとは実際の処理を行うコードをLambda関数として登録すれば完成です。
さっそく関数作りましょう。
Lambda関数の新規作成
サービス検索欄に「lambda」と入力し、Lambdaをクリックします。
関数の作成ボタンをクリックします。

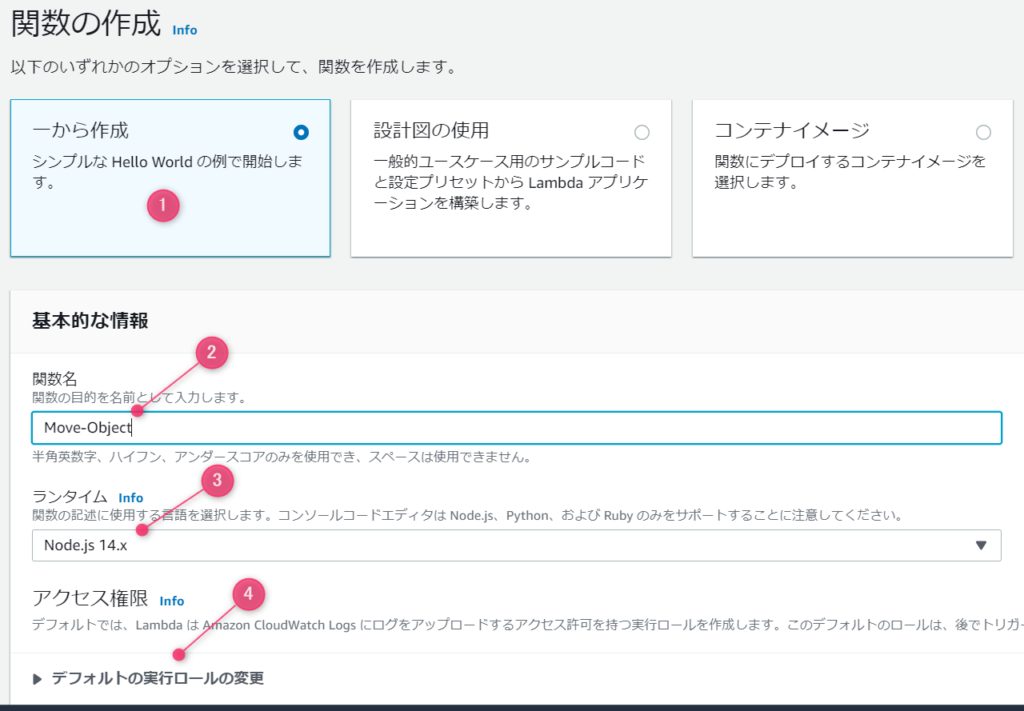
①「一から作成」を選択し、Lambda関数名を入力します。
②バケット同様、どんな処理を行う関数なのか分かりやすい名前をつけましょう。
③ランタイムはプルダウンから好きなものを選択することができます。今回は「Node.js」を使います。
④デフォルトの実行ロールをクリックして詳細設定を行います。
ここで既存のロールを使用する、を選択すると、さきほどIAMで作成したロールが選択できます。
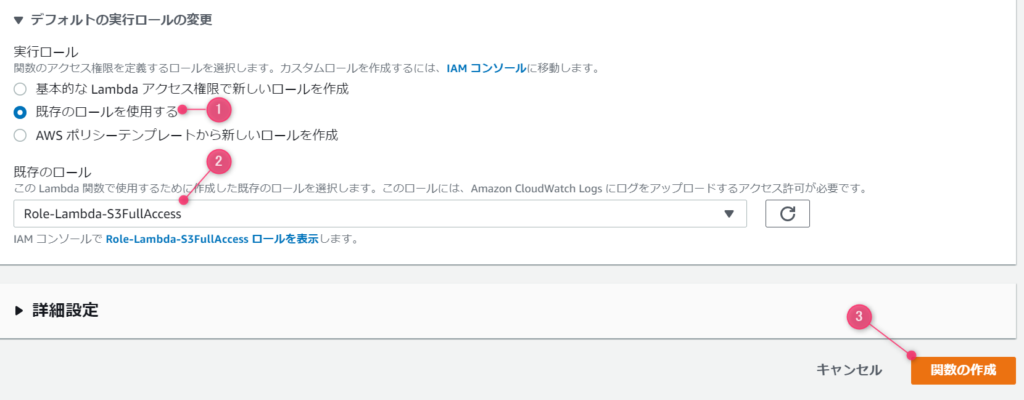
関数を作成すると、このような形で作った関数が表示されます。
トリガーの登録
トリガーとはこの関数が呼びたされるタイミングのことです。これを登録しないと関数は呼びされません。さっそくトリガーの追加ボタンを押しましょう。
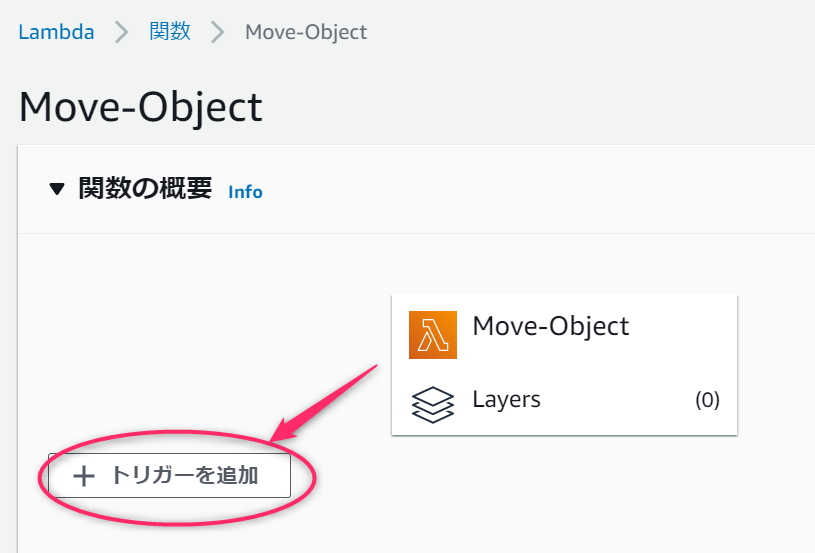
今回はS3バケットにファイルがアップロードされたタイミングで動く関数を作るので、次のようにセットします。
①トリガーはS3を選択
②監視対象のバケット名を選択します。今回は「object-input-box」バケットを選択します。
③対象のイベントはすべてのオブジェクト作成イベントを選択します。
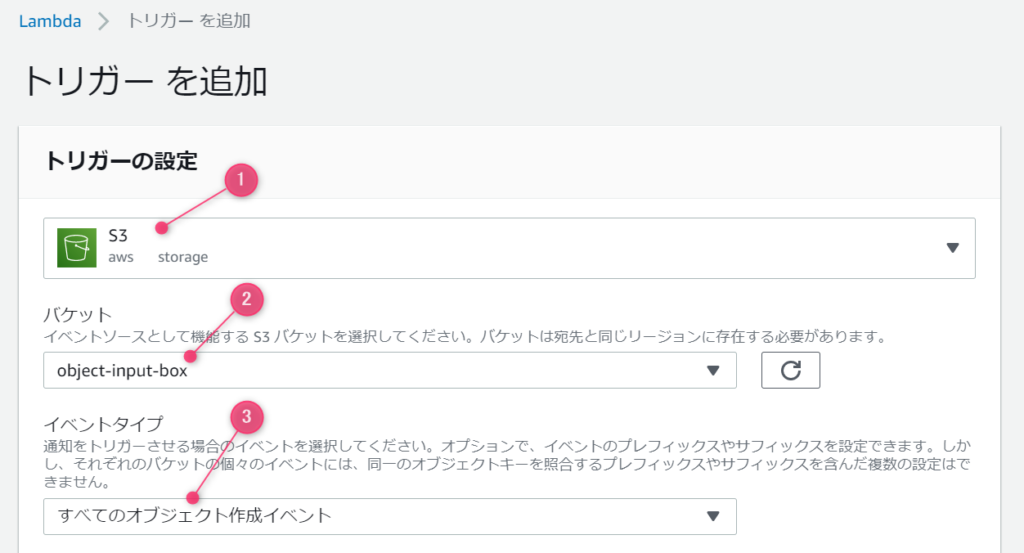
プレフィックスオプションとサフィックスについては、任意指定ですので、未入力でも良いです。今回は、バケット内のfilesフォルダに格納されたファイルのみ処理してみようと思いますので、プレフィックスに「file/」を指定します。
フォルダを指定したので、区切り文字の / を入れましたが、単純にファイルの先頭文字列をすることもできます。
また、特定の拡張子だけ処理したい場合など、サフィックスの方で指定します。
このように表示されれば、トリガーの設定は完了です。これでバケットにファイルをアップロードするとLambda関数が呼びたされるようになりました。

バケット間コピー・移動コードの作成
さて、いよいよプログラムを書きましょう。ここまで長かったですね~
関数にコードを追加するには、コードタブをクリックします。
自動でサンプルファイルが作成されますので、ここにファイルをコピー・移動させるJavaScriptコードを書いたら、Deployボタンを押して、プログラムを登録します。
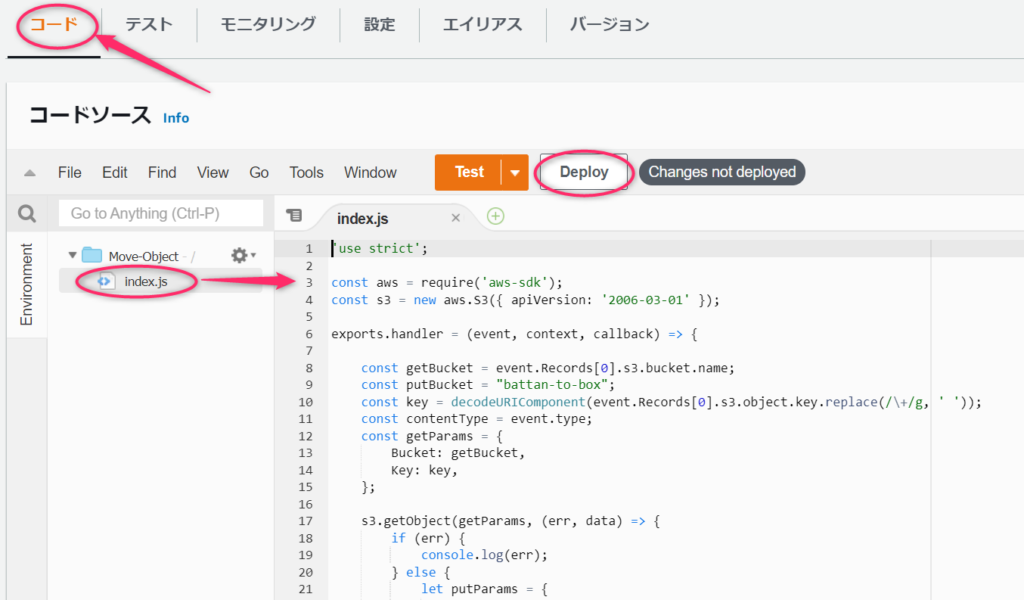
バケットを移動させるコードはこんな感じです。
以下にポイントをまとめます。
- S3バケットにファイルがアップロードされるとトリガーが発動してexports.handerがコールされます
- getBucketにはアップロードされたファイル名をセットします
- putBucket名は適宜変更してください
- s3.getObjectでアップロードされたファイルを取得します
- 取得に成功したら、s3.putObjectでputBucketに指定したバケットへ送信します
- 送信に成功したら、s3.deleteObjectでアップロードされたファイルをコピー元から削除します
- 移動ではなくコピーにしたい場合は、s3.deleteObjectをコールしないようにしてください
- エラー処理は入れてないので適宜書いてください
'use strict';
const aws = require('aws-sdk');
const s3 = new aws.S3({ apiVersion: '2006-03-01' });
exports.handler = (event, context, callback) => {
const getBucket = event.Records[0].s3.bucket.name;
const putBucket = 送信先バケット名;
const key = decodeURIComponent(event.Records[0].s3.object.key.replace(/\+/g, ' '));
const contentType = event.type;
const getParams = {
Bucket: getBucket,
Key: key,
};
s3.getObject(getParams, (err, data) => {
if (!err) {
let putParams = {
Bucket: putBucket,
Key: key,
Body: data.Body,
ContentType: contentType
};
s3.putObject(putParams, (err, data) => {
if (!err) {
s3.deleteObject(getParams, (err, data) => {
if (!err) {
callback(null);
}
});
}
});
}
});
};ネスト地獄が始まりかけていますが、短いコードなので堪忍してください。
動作確認
さて、ここまでできたら、実際に動かしてみましょう。
バケット内にフォルダを作成
さきほどトリガーをセットしたバケットに新しいフォルダを作ります。
トリガー設定時のプレフィックスに「files/」を指定したので、filesフォルダを作成してその中にファイルをアップロードしないとトリガーが発動しません。
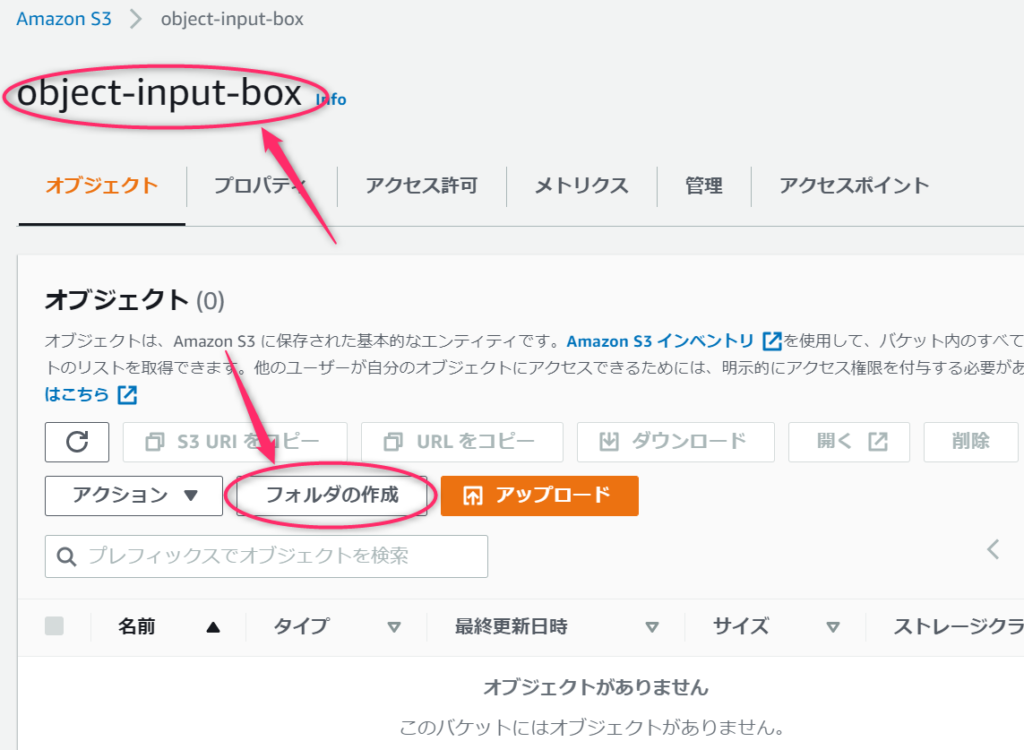
フォルダを作成します。暗号化はしてもしなくてもどちらでもいいです。

フォルダを作成すると、次のように表示されます。フォルダ名のリンクをクリックすると、フォルダの中に移動できます。
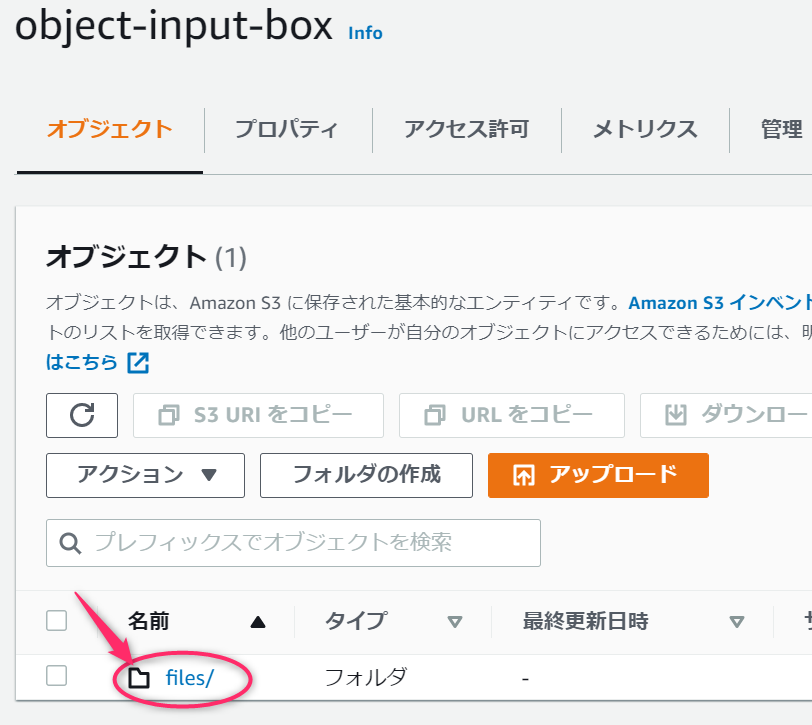
それでは、なにかファイルをアップロードしてみましょう。
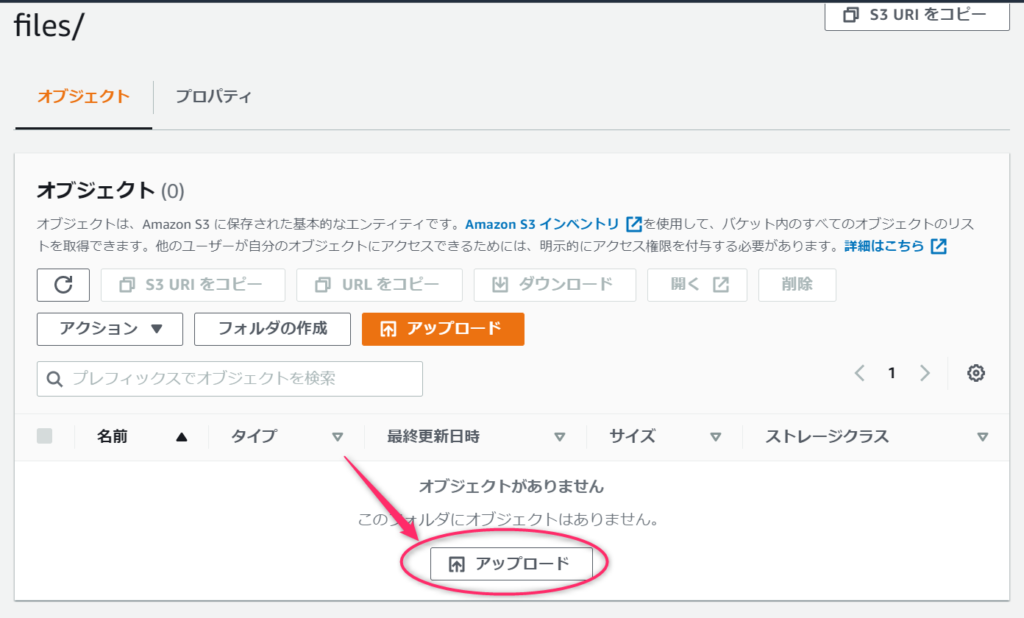
トリガーが発動するか確認
適当にパソコン内に転がっていた写真ファイルをアップロードしてみました。
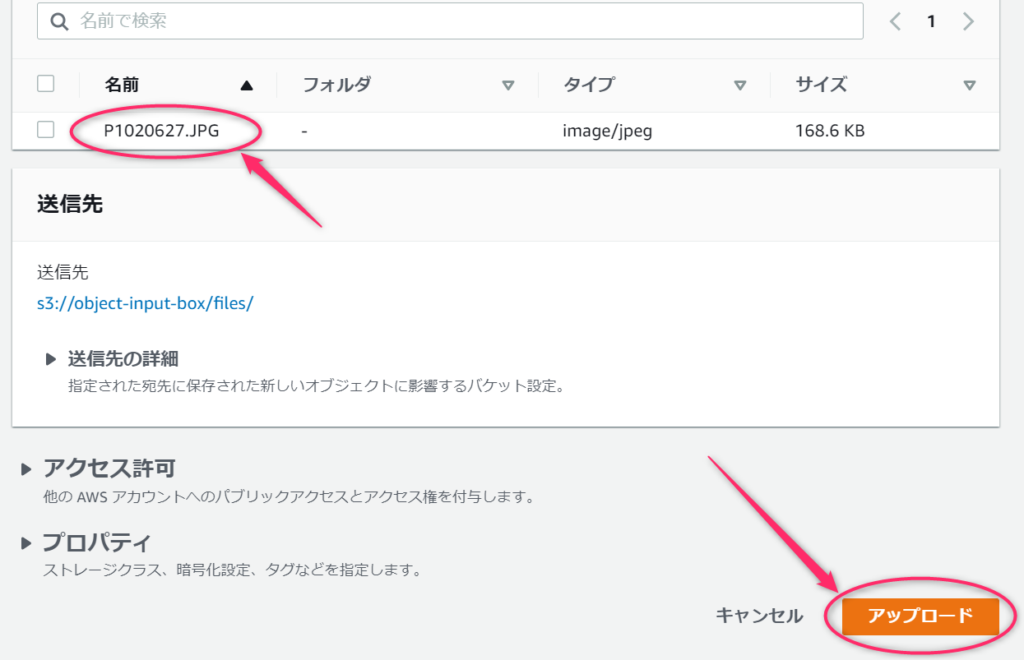
確かにファイルがアップロードされました。
アップロードを検知して処理が呼び出されるはずです。プログラムでは、読み込み⇒別バケットへコピー⇒削除という順番でしたので、直後はまだファイルが一覧に表示されますが、少し間をおいて画面を更新すると、一覧から消えると思います。処理が早く動けば表示すらされないかもしれません。
元バケットから削除する処理を入れているのにファイルが消えない場合はうまく動作していない可能性があります。
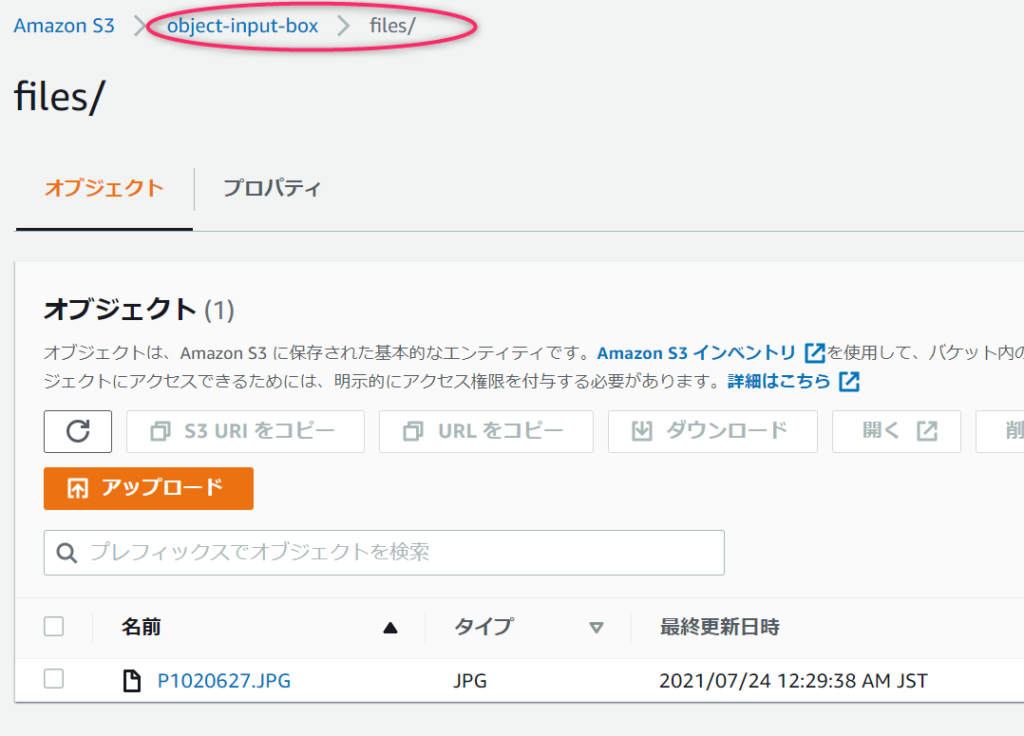
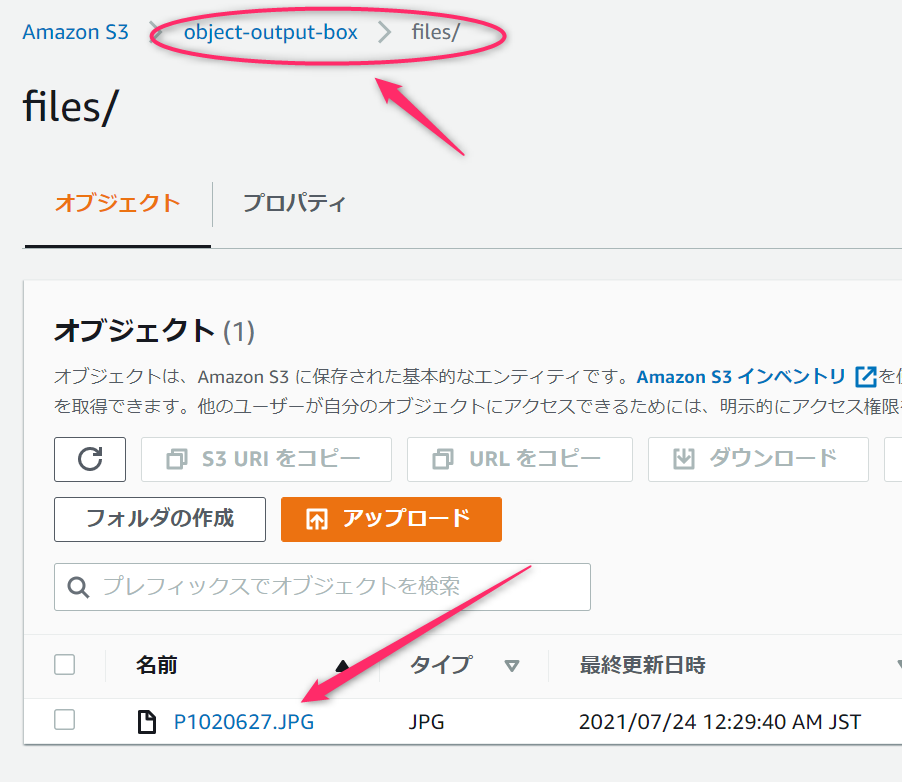
コピー・移動先バケットを見に行きましょう。
おおお、アップロードしたファイルがこちらのバケットに自動でコピー・移動できていますね!
コピー・移動先のバケットにはフォルダを作らなくても大丈夫です。S3のフォルダは疑似フォルダで実はオブジェクト名の一部なのでなければ自動で作られます。
まとめ
どうでしたか?
AWS Lambda便利ですよね。
ちょっとした処理をするのにわざわざEC2インスタンスを立ち上げるのは面倒ですし、コストもかかります。Lambdaは共通のAmazon Linux 2で実行されるため、わざわざ自前でサーバーインスタンスを立ち上げなくても処理実行時だけ間借りさせてもらって実行できます。
但し、お手軽な反面、複雑な処理を行うのは難しいので、すべてLambdaでやろうとすると限界を迎えます。要は使い所だと思います。
プログラミングは独学ではなかなか難しい時もあります。そんな時はプログラミングスクールで教わってしまうのも上達への近道です。

サーバレス開発は盛り上がってきています。お客様からサーバレスでサービスを構築したいというオーダーも最近ではよく見かけます。是非、理解を深めて活用していきましょう。



コメント